



Aproximadamente 400.000 PERSONAS están suscritas a la cuenta de YouTube Rob the Robot – Videos de aprendizaje para niños. En un video de 2020, el humanoide animado y sus amigos visitan un planeta con temática de estadio e intentan hazañas inspiradas en Heracles. Sus aventuras son adecuadas para la escuela primaria, pero los lectores jóvenes que activan los subtítulos automáticos de YouTube pueden ampliar su vocabulario. En un momento, los algoritmos de YouTube escuchan mal la palabra «valiente» y subtitulan a un personaje que aspira a ser «fuerte y violador como Heracles».

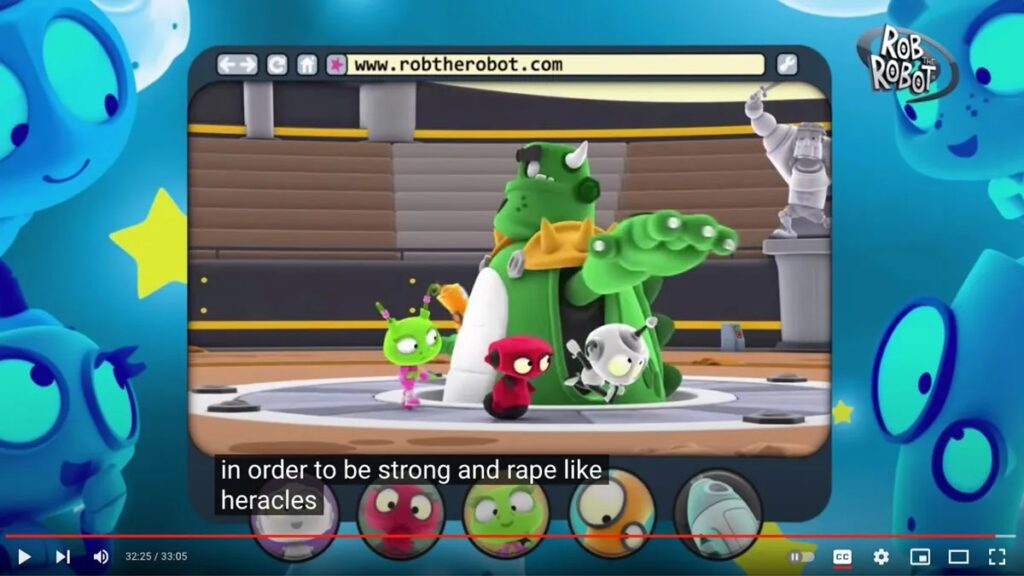
Un nuevo estudio de los subtítulos algorítmicos de YouTube en videos dirigidos a niños documenta cómo el texto a veces se desvía hacia un lenguaje muy adulto. En una muestra de más de 7000 videos de los 24 canales infantiles mejor calificados, el 40 por ciento mostró palabras en sus subtítulos que se encuentran en una lista de 1300 términos «tabú», extraídos en parte de un estudio sobre maldiciones. En aproximadamente el 1 por ciento de los videos, los subtítulos incluían palabras de una lista de 16 términos «altamente inapropiados», y los algoritmos de YouTube probablemente agregaron las palabras «perra», «bastardo» o «pene».
Algunos videos publicados en Ryan’s World, un importante canal para niños con más de 30 millones de suscriptores, ilustran el problema. En uno, la frase «También deberías comprar maíz» aparece en los subtítulos como «también deberías comprar pornografía». En otros videos, una «toalla de playa» se transcribe como una «toalla de perra», «buster» se convierte en «bastardo», un «cangrejo» se convierte en una «basura» y un video artesanal sobre cómo hacer una casa de muñecas con el tema de un monstruo presenta un » cama por pene.”


“Es sorprendente e inquietante”, dice Ashique KhudaBukhsh, profesor asistente en el Instituto de Tecnología de Rochester que investigó el problema con los colaboradores Krithika Ramesh y Sumeet Kumar en la Escuela de Negocios de la India en Hyderabad.
Los subtítulos automáticos no están disponibles en YouTube Kids, la versión del servicio dirigida a los niños. Pero muchas familias usan la versión estándar de YouTube, donde se les puede ver. Pew Research Center informó en 2020 que el 80 por ciento de los padres de niños de 11 años o menos dijeron que sus hijos vieron contenido de YouTube; más del 50 por ciento de los niños lo hacían a diario.
KhudaBukhsh espera que el estudio llame la atención sobre un fenómeno que, según él, ha recibido poca atención por parte de las empresas tecnológicas y los investigadores y que denomina «alucinación de contenido inapropiado», cuando los algoritmos agregan material inadecuado que no está presente en el contenido original. Piense en ello como la otra cara de la moneda de la observación común de que el autocompletado en los teléfonos inteligentes a menudo filtra el lenguaje de los adultos hasta un grado molesto.
La portavoz de YouTube, Jessica Gibby, dice que se recomienda que los niños menores de 13 años usen YouTube Kids, donde no se pueden ver los subtítulos automáticos. En la versión estándar de YouTube, dice que la función mejora la accesibilidad. “Trabajamos continuamente para mejorar los subtítulos automáticos y reducir los errores”, dice. Alafair Hall, portavoz de Pocket.watch, un estudio de entretenimiento infantil que publica contenido de Ryan’s World, dice en un comunicado que la compañía está «en contacto cercano e inmediato con nuestros socios de plataforma, como YouTube, que trabajan para actualizar los subtítulos de video incorrectos». El operador del canal Rob the Robot no pudo ser contactado para hacer comentarios.
Las alucinaciones inapropiadas no son exclusivas de YouTube o de los subtítulos de los videos. Un reportero de WIRED descubrió que la transcripción de una llamada telefónica procesada por la startup Trint mostraba a Negar, un nombre de mujer de origen persa, como una variante de la palabra N, aunque suena claramente diferente al oído humano. El CEO de Trint, Jeffrey Kofman, dice que el servicio tiene un filtro de blasfemias que elimina automáticamente «una lista muy pequeña de palabras». La ortografía particular que apareció en la transcripción de WIRED no estaba en esa lista, dijo Kofman, pero se agregará.
“Los beneficios de la conversión de voz a texto son innegables, pero hay puntos ciegos en estos sistemas que pueden requerir controles y equilibrios”, dice KhudaBukhsh.
Esos puntos ciegos pueden parecer sorprendentes para los humanos que dan sentido al habla en parte al comprender el contexto más amplio y el significado de las palabras de una persona. Los algoritmos han mejorado su capacidad para procesar el lenguaje, pero aún carecen de la capacidad para una comprensión más completa, algo que ha causado problemas a otras empresas que dependen de las máquinas para procesar el texto. Una startup tuvo que renovar su juego de aventuras después de que se descubriera que a veces describía escenarios sexuales que involucraban a menores.
Los algoritmos de aprendizaje automático «aprenden» una tarea al procesar grandes cantidades de datos de entrenamiento, en este caso, archivos de audio y transcripciones coincidentes. KhudaBukhsh dice que el sistema de YouTube probablemente inserta blasfemias a veces porque sus datos de entrenamiento incluían principalmente habla de adultos y menos de niños. Cuando los investigadores verificaron manualmente los ejemplos de palabras inapropiadas en los subtítulos, a menudo aparecían con el habla de niños o personas que parecían no ser hablantes nativos de inglés. Estudios anteriores han encontrado que los servicios de transcripción de Google y otras compañías tecnológicas importantes cometen más errores para los hablantes no blancos y menos errores para el inglés estadounidense estándar, en comparación con los dialectos regionales de EE. UU.
Rachael Tatman, una lingüista que fue coautora de uno de esos estudios anteriores, dice que una simple lista de bloqueo de palabras que no se deben usar en los videos de YouTube para niños abordaría muchos de los peores ejemplos encontrados en la nueva investigación. “Que aparentemente no haya ninguno es un descuido de ingeniería”, dice ella.
Una lista negra también sería una solución imperfecta, dice Tatman. Se pueden construir frases inapropiadas con palabras individualmente inocuas. Un enfoque más sofisticado sería ajustar el sistema de subtítulos para evitar el lenguaje adulto cuando se trabaja con contenido para niños, pero Tatman dice que no sería perfecto. El software de aprendizaje automático que funciona con el lenguaje puede orientarse estadísticamente en ciertas direcciones, pero no se programa fácilmente para respetar el contexto que parece obvio para los humanos. “Los modelos de lenguaje no son herramientas de precisión”, dice Tatman.
KhudaBbukhsh y sus colaboradores idearon y probaron sistemas para corregir palabras tabú en las transcripciones, pero incluso los mejores insertaron la palabra correcta menos de un tercio de las veces en las transcripciones de YouTube. Presentarán su investigación en la conferencia anual de la Asociación para el Avance de la Inteligencia Artificial este mes y han publicado datos de su estudio para ayudar a otros a explorar el problema.
El equipo también ejecutó el audio de los videos de YouTube de los niños a través de un servicio de transcripción automatizado ofrecido por Amazon. También a veces cometió errores que hicieron que el contenido fuera más nervioso. La portavoz de Amazon, Nina Lindsey, se negó a comentar, pero proporcionó enlaces a la documentación que asesora a los desarrolladores sobre cómo corregir o filtrar las palabras no deseadas. Los resultados de los investigadores sugieren que esas opciones podrían ser adecuadas al transcribir contenido para niños: «Fluffy» se convirtió en la palabra F en la transcripción de un video sobre un juguete; un presentador de video pidió a los espectadores que enviaran no «ideas artesanales» sino «ideas de mierda».